대규모 언어 모델은 매우 유능한 사용 사례인 ChatGPT가 밤새 성공을 거둔 후 최근 엄청난 명성을 얻었습니다. ChatGPT 및 기타 ChatBot의 성공을 보고 많은 사람과 조직이 이러한 소프트웨어를 구동하는 기술을 탐색하는 데 관심을 갖게 되었습니다.
대규모 언어 모델은 기계 번역, 음성 인식, 질문 응답 및 텍스트 요약과 같은 다양한 자연어 처리 응용 프로그램의 작업을 가능하게 하는 이 소프트웨어의 중추입니다. LLM에 대해 자세히 알아보고 최상의 결과를 위해 LLM을 최적화하는 방법에 대해 알아보십시오.
대규모 언어 모델 또는 ChatGPT란 무엇입니까?
대규모 언어 모델은 인공 신경망과 대규모 데이터 사일로를 활용하여 NLP 애플리케이션을 구동하는 기계 학습 모델입니다. LLM은 많은 양의 데이터에 대한 교육을 통해 자연어의 다양한 복잡성을 캡처할 수 있는 능력을 얻었으며 다음과 같은 용도로 활용했습니다.
- 새 텍스트 생성
- 기사 및 구절 요약
- 데이터 추출
- 텍스트 재작성 또는 패러프레이징
- 데이터 분류
LLM의 인기 있는 예로는 BERT, Chat GPT-3 및 XLNet이 있습니다. 이러한 모델은 수억 개의 텍스트에 대해 학습되며 모든 유형의 개별 사용자 쿼리에 대해 가치 있는 솔루션을 제공할 수 있습니다.
대규모 언어 모델의 인기 사용 사례
다음은 LLM의 가장 널리 사용되는 주요 사용 사례 중 일부입니다.
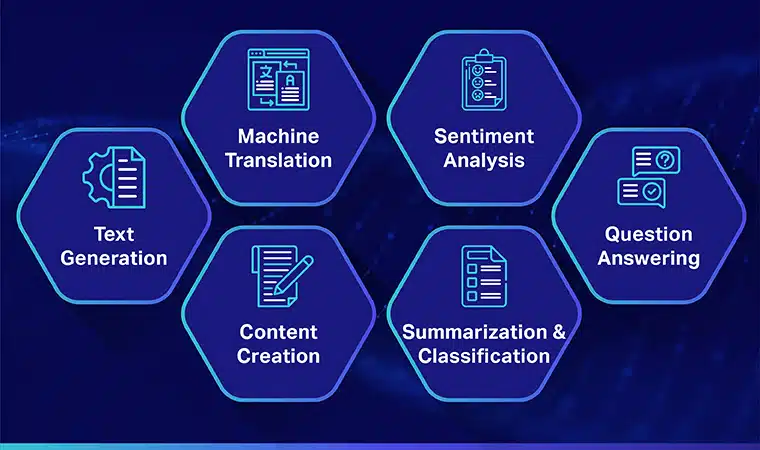
텍스트 생성
대규모 언어 모델은 인공 지능 및 전산 언어학 지식을 활용하여 자연어 텍스트를 자동으로 생성하고 기사 작성, 노래 작성 또는 사용자와의 채팅과 같은 다양한 의사 소통 사용자 요구 사항을 완료합니다.
기계 번역
LLM은 두 언어 간에 텍스트를 번역하는 데에도 사용할 수 있습니다. 이 모델은 반복 신경망과 같은 심층 학습 알고리즘을 활용하여 소스 및 대상 언어의 언어 구조를 학습합니다. 따라서 소스 텍스트를 대상 언어로 번역하는 데 사용됩니다.
콘텐츠제작
LLM은 이제 기계가 블로그 게시물, 기사 및 기타 형식의 콘텐츠를 생성하는 데 사용할 수 있는 일관되고 논리적인 콘텐츠를 생성할 수 있도록 했습니다. 이 모델은 광범위한 딥 러닝 지식을 사용하여 사용자가 읽을 수 있는 고유한 형식으로 콘텐츠를 이해하고 구조화합니다.
감정 분석
레이블이 지정된 텍스트에서 감정 상태와 감정을 식별하고 분류하도록 모델을 훈련하는 대규모 언어 모델의 흥미로운 사용 사례입니다. 이 소프트웨어는 긍정, 부정, 중립과 같은 감정과 다양한 제품 및 서비스에 대한 고객 의견 및 리뷰에 대한 통찰력을 얻는 데 도움이 되는 기타 복잡한 감정을 감지할 수 있습니다.
텍스트의 이해, 요약 및 분류
LLM은 AI 소프트웨어가 텍스트와 그 맥락을 이해할 수 있는 실용적인 프레임워크를 제공합니다. 대량의 데이터를 이해하고 분석하도록 모델을 훈련함으로써 LLM은 AI 모델이 다양한 형식과 패턴으로 텍스트를 이해, 요약 및 분류할 수 있도록 합니다.
질문 답변
대규모 언어 모델을 사용하면 QA 시스템이 사용자의 자연어 쿼리를 정확하게 감지하고 응답할 수 있습니다. 이 사용 사례의 가장 인기 있는 애플리케이션 중 하나는 ChatGPT 및 BERT로, 쿼리의 컨텍스트를 분석하고 대규모 텍스트 모음을 검색하여 사용자 쿼리에 대한 관련 답변을 찾습니다.
[ 또한 읽기: 언어 처리의 미래: 대규모 언어 모델 및 예제 ]

LLM을 성공시키기 위한 3가지 필수 조건
효율성을 높이고 대규모 언어 모델을 성공적으로 수행하려면 다음 세 가지 조건을 정확하게 충족해야 합니다.
모델 학습을 위한 엄청난 양의 데이터 존재
LLM은 효율적이고 최적의 결과를 제공하는 모델을 교육하기 위해 많은 양의 데이터가 필요합니다. LLM이 성능과 정확도를 향상시키기 위해 활용하는 전이 학습 및 자체 감독 사전 교육과 같은 특정 방법이 있습니다.
모델에 대한 복잡한 패턴을 용이하게 하기 위해 뉴런 레이어 구축
대규모 언어 모델은 데이터의 복잡한 패턴을 이해하도록 특별히 훈련된 다양한 뉴런 계층으로 구성되어야 합니다. 깊은 층의 뉴런은 얕은 층보다 복잡한 패턴을 더 잘 이해할 수 있습니다. 모델은 단어 간의 연관성, 함께 등장하는 주제, 품사 간의 관계를 학습할 수 있습니다.
사용자별 작업을 위한 LLM 최적화
레이어, 뉴런 및 활성화 기능의 수를 변경하여 특정 작업에 대해 LLM을 조정할 수 있습니다. 예를 들어, 문장에서 다음 단어를 예측하는 모델은 일반적으로 처음부터 새 문장을 생성하도록 설계된 모델보다 적은 수의 레이어와 뉴런을 사용합니다.
대규모 언어 모델의 인기 있는 예
다음은 다양한 산업 분야에서 널리 사용되는 LLM의 몇 가지 대표적인 예입니다.
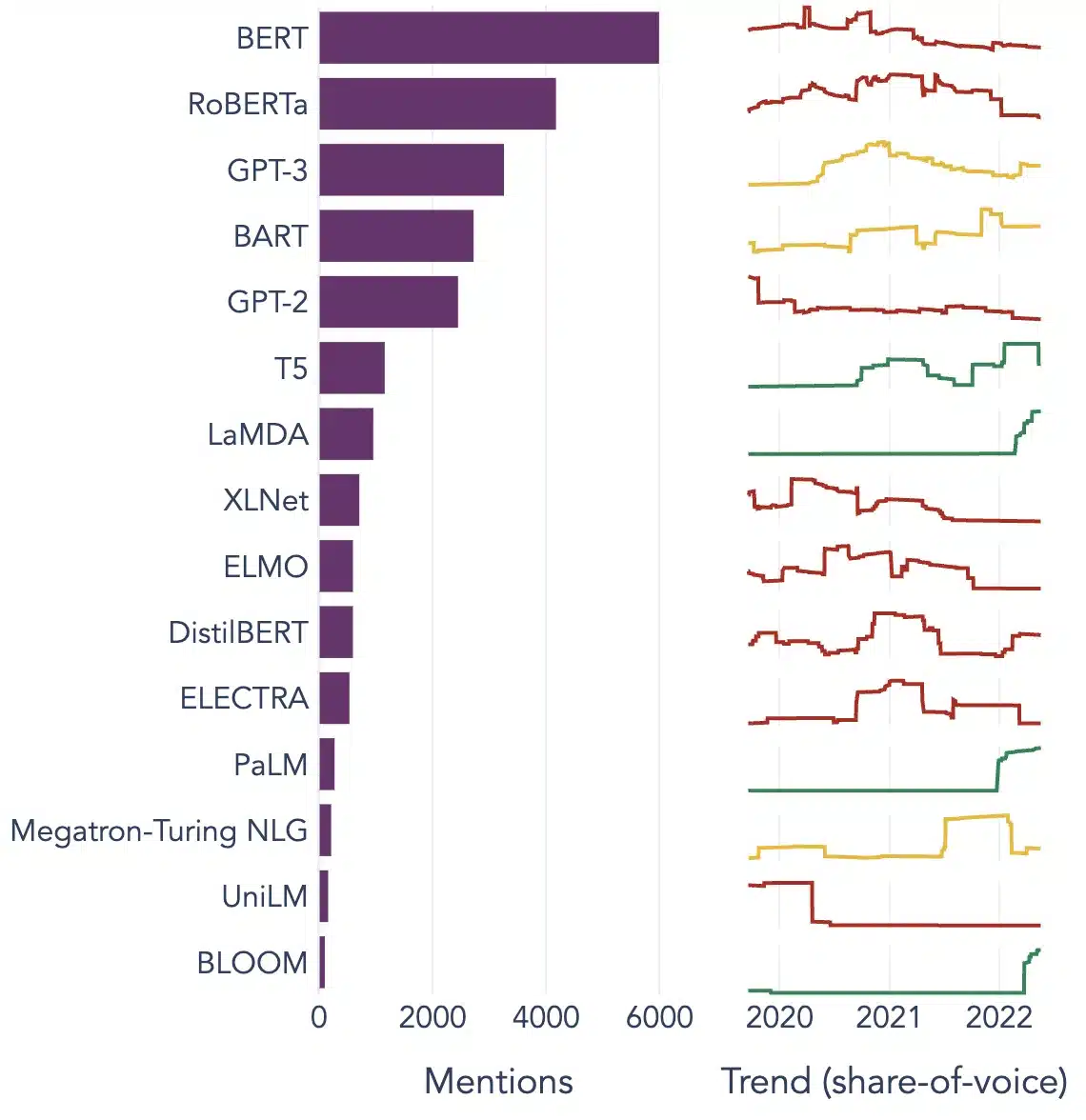
이미지 출처 : 데이터 과학을 향하여
결론
LLM은 견고하고 정확한 언어 이해 기능과 완벽한 사용자 경험을 제공하는 솔루션을 제공함으로써 NLP를 혁신할 수 있는 잠재력을 보고 있습니다. 그러나 LLM을 보다 효율적으로 만들기 위해 개발자는 고품질 음성 데이터를 활용하여 보다 정확한 결과를 생성하고 매우 효과적인 AI 모델을 생성해야 합니다.
Shaip은 50개 이상의 언어와 여러 형식으로 광범위한 음성 데이터를 제공하는 선도적인 AI 기술 솔루션 중 하나입니다. LLM에 대해 자세히 알아보고 프로젝트에 대한 안내를 받으십시오. 오늘날 Shaip 전문가.