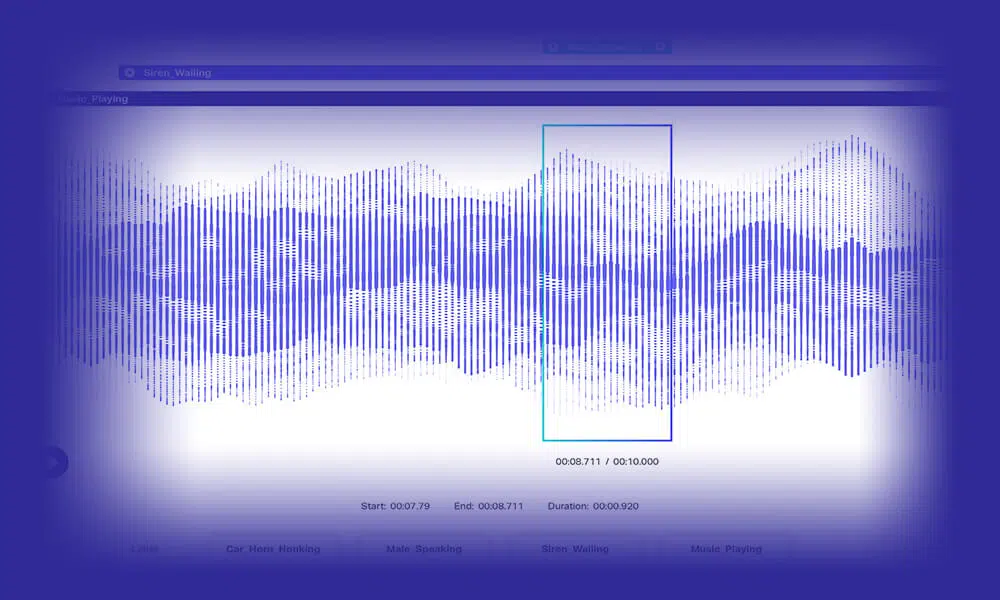


오디오 전사
트럭에 정확하게 기록된 음성/오디오 데이터를 공급하여 지능형 NLP 모델을 개발합니다. Shaip에서는 표준 오디오, 축자 및 다국어 전사를 포함하여 더 넓은 선택 범위에서 선택할 수 있습니다. 또한 추가 화자 식별자 및 타임스탬프 데이터를 사용하여 모델을 훈련할 수 있습니다.
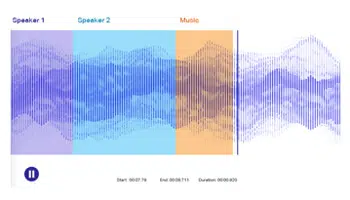
음성 라벨링
음성 또는 오디오 라벨링은 사운드를 분리하고 특정 메타데이터로 라벨링하는 것과 관련된 표준 주석 기술입니다. 이 기술의 핵심은 오디오 조각의 소리를 존재론적으로 식별하고 정확하게 주석을 달아 훈련 데이터 세트를 보다 포괄적으로 만드는 것입니다.

오디오 분류
음성 주석 회사에서 콘텐츠에 따라 오디오 녹음을 분석하는 것과 관련하여 AI를 완벽하게 훈련시키는 데 사용됩니다. 오디오 분류를 통해 기계는 음성과 소리를 식별할 수 있으며 보다 능동적인 훈련 체제의 일환으로 둘을 구별할 수 있습니다.

다국어 오디오 데이터 서비스
다국어 오디오 데이터를 수집하는 것은 주석자가 그에 따라 레이블을 지정하고 분할할 수 있는 경우에만 유용합니다. 다국어 오디오 데이터 서비스는 언어의 다양성을 기반으로 음성에 주석을 달고 관련 AI에 의해 완벽하게 식별 및 구문 분석되는 것과 관련하여 편리합니다.

자연어
말
NLU는 의미론, 방언, 문맥, 강세 등과 같은 가장 작은 세부사항을 분류하기 위해 인간의 말에 주석을 다는 것과 관련이 있습니다. 이러한 형태의 주석이 달린 데이터는 가상 비서와 챗봇을 더 잘 훈련시키는 데 적합합니다.
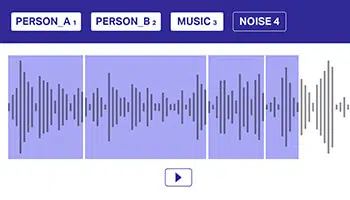
다중 레이블
주석
여러 레이블에 의존하여 오디오 데이터에 주석을 추가하는 것은 모델이 겹치는 오디오 소스를 구별하는 데 중요합니다. 이 접근 방식에서 오디오 데이터 세트는 더 나은 의사 결정을 위해 모델에 명시적으로 전달해야 하는 하나 이상의 클래스에 속할 수 있습니다.

화자 분할
여기에는 입력 오디오 파일을 개별 스피커와 관련된 동종 세그먼트로 분할하는 작업이 포함됩니다. 분할은 화자 경계를 식별하고 오디오 파일을 세그먼트로 그룹화하여 개별 화자의 수를 결정하는 것을 의미합니다. 이 프로세스는 콜 센터 대화, 의료 및 법률 대화, 회의의 대화 분석 및 전사를 자동화하는 데 도움이 됩니다.

음성 표기
오디오를 일련의 단어로 변환하는 일반 전사와 달리 음성 전사는 단어가 발음되는 방식을 기록하고 음성 기호를 사용하여 소리를 시각적으로 나타냅니다. 음성 표기를 사용하면 여러 방언에서 동일한 언어의 발음 차이를 더 쉽게 확인할 수 있습니다.

사람들
전담 및 훈련된 팀:
- 데이터 생성, 라벨링 및 QA를 위한 30,000명 이상의 공동 작업자
- 자격을 갖춘 프로젝트 관리 팀
- 경험이 풍부한 제품 개발 팀
- 인재 풀 소싱 및 온보딩 팀

방법
최고의 공정 효율성은 다음을 통해 보장됩니다.
- 강력한 6시그마 스테이지 게이트 프로세스
- 6시그마 블랙벨트로 구성된 전담 팀 – 핵심 프로세스 소유자 및 품질 준수
- 지속적인 개선 및 피드백 루프

플랫폼
특허 받은 플랫폼은 다음과 같은 이점을 제공합니다.
- 웹 기반 엔드 투 엔드 플랫폼
- 완벽한 품질
- 더 빠른 TAT
- 원활한 전달
사람들
전담 및 훈련된 팀:
- 데이터 생성, 라벨링 및 QA를 위한 30,000명 이상의 공동 작업자
- 자격을 갖춘 프로젝트 관리 팀
- 경험이 풍부한 제품 개발 팀
- 인재 풀 소싱 및 온보딩 팀
방법
최고의 공정 효율성은 다음을 통해 보장됩니다.
- 강력한 6시그마 스테이지 게이트 프로세스
- 6시그마 블랙벨트로 구성된 전담 팀 – 핵심 프로세스 소유자 및 품질 준수
- 지속적인 개선 및 피드백 루프
플랫폼
특허 받은 플랫폼은 다음과 같은 이점을 제공합니다.
- 웹 기반 엔드 투 엔드 플랫폼
- 완벽한 품질
- 더 빠른 TAT
- 원활한 전달

텍스트 주석
서비스
우리는 엔티티 주석, 텍스트 분류, 감정 주석 및 기타 관련 도구를 사용하여 철저한 데이터 세트에 주석을 추가하여 텍스트 데이터 교육을 준비하는 것을 전문으로 합니다.

이미지 주석
서비스
우리는 컴퓨터 비전 모델을 훈련하기 위해 분류된 이미지 데이터 세트에 레이블을 지정하는 것을 자랑스럽게 생각합니다. 관련 기술 중 일부에는 경계 인식 및 이미지 분류가 포함됩니다.

비디오 주석
서비스
Shaip은 Computer Vision 모델 교육을 위한 고급 비디오 라벨링 서비스를 제공합니다. 목표는 패턴 인식, 객체 감지 등과 같은 도구로 데이터 세트를 사용할 수 있도록 하는 것입니다.


