

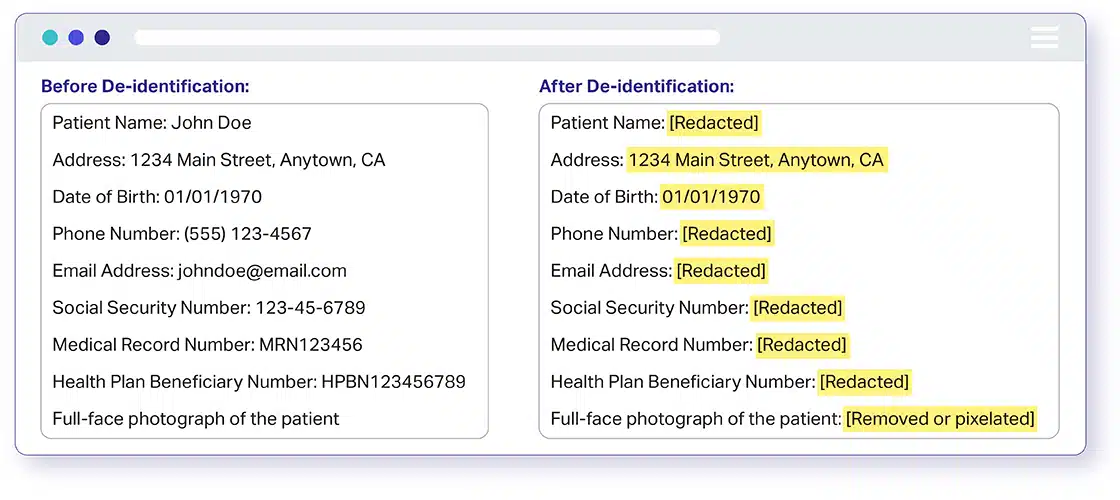
개인 식별 정보(PII)
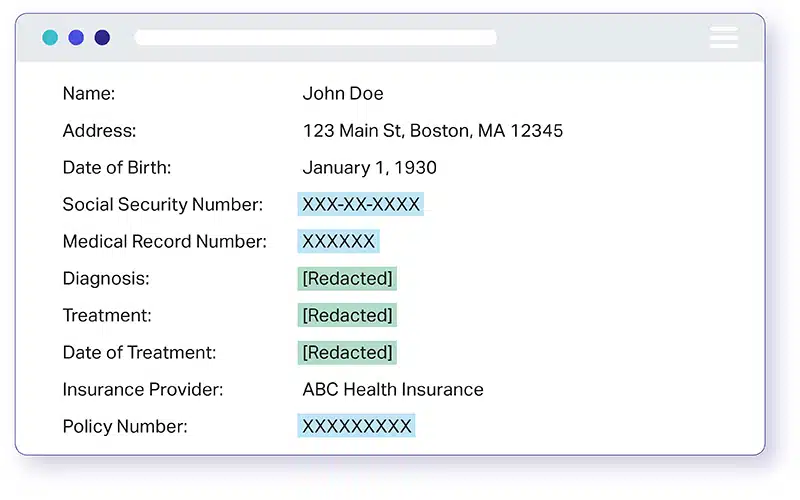
PII 데이터 비식별화 또는 PII 데이터 익명화는 식별된 정보가 적용되는 개인의 신원을 허용하거나 직접 또는 간접적 수단으로 합리적으로 추론할 수 있는 모든 정보를 비식별화하는 프로세스입니다. 간단히 말해 개인 식별 정보(PII)는 특정 개인에게 연락하거나, 찾거나, 식별할 수 있는 모든 데이터입니다.
개인을 식별하는 데 사용될 수 있는 HIPAA 비식별화 표준 식별자 또는 데이터 요소에는 다음이 포함됩니다.
| PII에는 이름, 이메일, 집 주소, 전화번호가 포함됩니다. | |
|---|---|
| 독립 실행형인 경우 | 다른 식별자와 쌍을 이루는 경우 |
| 사회 보장 번호 | 시민권 또는 이민 신분 |
| 운전 면허증 또는 주 신분증 | 어머니의 처녀 이름 |
| 여권 번호 | 인종 또는 종교 |
| 외국인 등록 번호 | 성적 취향 |
| 금융 계좌 번호 | 계정 비밀번호 |
| 생체 인식 식별자 | 주민등록번호 마지막 4자리 |
| 전화 번호 | 생년월일 |
| 이메일 주소 | 범죄 기록 |
| 풀페이스 사진 | |
보호 건강 정보 (PHI)
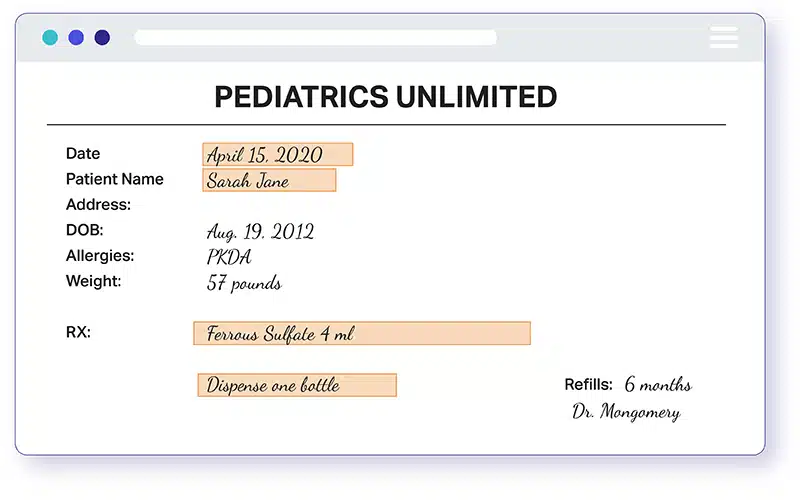
PHI 데이터 비식별화 또는 PHI 데이터 익명화는 개인을 식별하는 데 사용할 수 있는 의료 기록의 정보를 비식별화하는 프로세스입니다. 진단, 치료 등 의료 서비스를 제공하는 과정에서 생성, 사용 또는 공개된 것. 간단히 말해 보호되는 건강 정보(PHI)는 특정 개인에게 연락하거나, 찾거나, 식별할 수 있는 모든 데이터입니다.
개인을 식별하는 데 사용할 수 있는 HIPAA 식별자 또는 데이터 요소는 다음과 같습니다.
- 의료 이미지, 기록, 건강 보험 수혜자, 증명서, 사회 보장 및 계좌 번호
- 개인의 과거, 현재 또는 미래의 건강이나 상태
- 개인에 대한 의료 제공에 대한 과거, 현재 또는 미래의 지불
- 생년월일, 퇴원일, 사망일, 행정처분 등 개인과 직접 연결된 모든 날짜



사람들
전담 및 훈련된 팀:
- 데이터 생성, 라벨링 및 QA를 위한 30,000명 이상의 공동 작업자
- 자격을 갖춘 프로젝트 관리 팀
- 경험이 풍부한 제품 개발 팀
- 인재 풀 소싱 및 온보딩 팀

방법
최고의 공정 효율성은 다음을 통해 보장됩니다.
- 강력한 6시그마 스테이지 게이트 프로세스
- 6시그마 블랙벨트로 구성된 전담 팀 – 핵심 프로세스 소유자 및 품질 준수
- 지속적인 개선 및 피드백 루프

플랫폼
특허 받은 플랫폼은 다음과 같은 이점을 제공합니다.
- 웹 기반 엔드 투 엔드 플랫폼
- 완벽한 품질
- 더 빠른 TAT
- 원활한 전달
사람들
전담 및 훈련된 팀:
- 데이터 생성, 라벨링 및 QA를 위한 30,000명 이상의 공동 작업자
- 자격을 갖춘 프로젝트 관리 팀
- 경험이 풍부한 제품 개발 팀
- 인재 풀 소싱 및 온보딩 팀
방법
최고의 공정 효율성은 다음을 통해 보장됩니다.
- 강력한 6시그마 스테이지 게이트 프로세스
- 6시그마 블랙벨트로 구성된 전담 팀 – 핵심 프로세스 소유자 및 품질 준수
- 지속적인 개선 및 피드백 루프
플랫폼
특허 받은 플랫폼은 다음과 같은 이점을 제공합니다.
- 웹 기반 엔드 투 엔드 플랫폼
- 완벽한 품질
- 더 빠른 TAT
- 원활한 전달



임상 NLP를 만드는 것은 해결하기 위해 엄청난 도메인 전문 지식이 필요한 중요한 작업입니다. 이 분야에서 Google보다 몇 년 앞서 있다는 것을 분명히 알 수 있습니다. 나는 당신과 함께 일하고 당신을 확장하고 싶습니다.
구글, 주식 회사 책임자
내 엔지니어링 팀은 의료 음성 API를 개발하는 동안 Shaip의 팀과 2년 이상 협력했습니다. 우리는 의료 관련 NLP에서 수행한 작업과 복잡한 데이터 세트로 달성할 수 있는 것에 깊은 인상을 받았습니다.
구글, 주식 회사 엔지니어링 책임자