

텍스트 분류
내용 유형, 의도, 감정 및 주제를 기반으로 텍스트를 분류하는 데 중점을 둔 텍스트 주석에 관한 가장 기본적인 접근 방식입니다. 일단 분류되면, 데이터 세트는 사전 정의된 세그먼트의 일부로 시스템에 공급되며, 기계는 응답을 생성하기 위해 액세스할 수 있습니다.
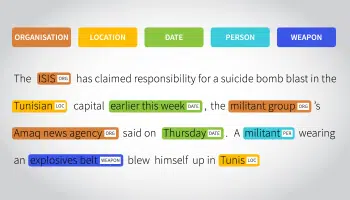
언어 주석
원래 말뭉치 주석으로 불렸던 이 형식의 텍스트 데이터 세트 레이블링은 오디오 및 텍스트의 언어 세부 정보에 중점을 둡니다. 또한 음성 주석, 의미 주석 비트, POS 태깅 등도 필요합니다. 이 접근 방식은 기계 번역 모델을 훈련할 때 적절합니다.

엔티티 주석
이 라벨링 방법은 챗봇 교육에서 매우 중요합니다. 여기서 초점은 데이터를 시스템에 공급하기 전에 엔터티를 추출, 위치 지정 및 태그 지정하는 데 있습니다. 챗봇 기반 인터페이스와 마찬가지로 형용사, 부사 등과 같은 이름 엔터티, 핵심 문구 및 POS가 중심이 됩니다.

엔티티 연결
애노테이터가 더 큰 데이터 리포지토리에서 엔터티를 추출하는 동안 의미를 전달하는 데이터 세트를 형성하려면 상호 연결되어야 합니다. 이것은 명확성을 통해 완전한 지식 데이터베이스를 설정하고 결국에는 종단 간 연결을 포함하는 몇 안 되는 텍스트 주석 도구 중 하나입니다. 예: 채팅 인터페이스에서 직접 URL 라우팅

SAO(주제 작업 개체)
텍스트에 작업으로 연결된 여러 엔터티가 포함된 경우. 예를 들어, 'John hits Jimmy'는 법률 기반 토론에 관한 레이블이 추가되는 엔티티 주석 및 텍스트 분류에 열려 있습니다. 그러나 모델이 문장을 이해하려면 SAO 데이터가 제공되어야 하며 John은 주체, Jimmy는 객체, 소송은 작업입니다.
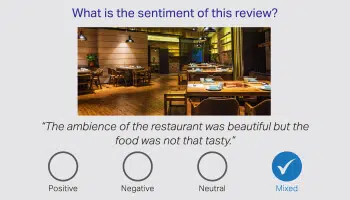
감정 주석
감정 주석은 감정적 레이블 지정을 처리하고 지능형 설정이 숨겨진 함축, 의견 및 특정 감정을 감지할 수 있도록 합니다. 주석가는 텍스트를 검토하고 부정적, 중립적 및 긍정적 감정으로 레이블을 지정하는 책임이 할당됩니다. 인텐트 주석은 쿼리의 욕구에 초점을 맞춥니다.

사람들
전담 및 훈련된 팀:
- 데이터 생성, 라벨링 및 QA를 위한 30,000명 이상의 공동 작업자
- 자격을 갖춘 프로젝트 관리 팀
- 경험이 풍부한 제품 개발 팀
- 인재 풀 소싱 및 온보딩 팀

방법
최고의 공정 효율성은 다음을 통해 보장됩니다.
- 강력한 6시그마 스테이지 게이트 프로세스
- 6시그마 블랙벨트로 구성된 전담 팀 – 핵심 프로세스 소유자 및 품질 준수
- 지속적인 개선 및 피드백 루프

플랫폼
특허 받은 플랫폼은 다음과 같은 이점을 제공합니다.
- 웹 기반 엔드 투 엔드 플랫폼
- 완벽한 품질
- 더 빠른 TAT
- 원활한 전달
사람들
전담 및 훈련된 팀:
- 데이터 생성, 라벨링 및 QA를 위한 30,000명 이상의 공동 작업자
- 자격을 갖춘 프로젝트 관리 팀
- 경험이 풍부한 제품 개발 팀
- 인재 풀 소싱 및 온보딩 팀
방법
최고의 공정 효율성은 다음을 통해 보장됩니다.
- 강력한 6시그마 스테이지 게이트 프로세스
- 6시그마 블랙벨트로 구성된 전담 팀 – 핵심 프로세스 소유자 및 품질 준수
- 지속적인 개선 및 피드백 루프
플랫폼
특허 받은 플랫폼은 다음과 같은 이점을 제공합니다.
- 웹 기반 엔드 투 엔드 플랫폼
- 완벽한 품질
- 더 빠른 TAT
- 원활한 전달
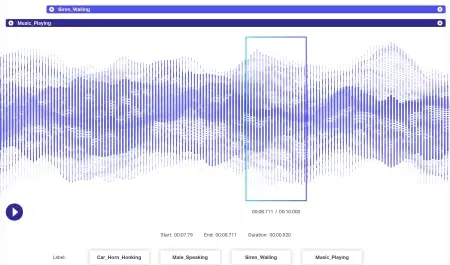
오디오 주석
서비스
음성 인식, 화자 분할, 감정 인식 등과 같은 관련 도구를 통해 오디오 소스, 음성 및 음성 관련 데이터 세트에 레이블을 지정하는 것은 Shaip의 전문 분야입니다.

이미지 주석
서비스
우리는 안목 있는 컴퓨터 비전 모델을 훈련하기 위해 분류된 이미지 데이터 세트에 레이블을 지정하는 것을 자랑스럽게 생각합니다. 관련 기술 중 일부에는 경계 인식 및 이미지 분류가 포함됩니다.

비디오 주석
서비스
Shaip은 Computer Vision 모델 교육을 위한 고급 비디오 라벨링 서비스를 제공합니다. 여기서 목표는 패턴 인식, 객체 감지 등과 같은 도구와 함께 데이터 세트를 사용할 수 있도록 하는 것입니다.


