


Q&A 쌍
텍스트 요약
이미지 캡션
오디오 생성
LLM 데이터 평가
LLM 데이터 비교
합성 대화 생성
이미지 요약, 평가 및 검증
Q&A 쌍
Q/A 쌍 생성
키워드 쿼리 생성
시퀀스 Q&A
RAG Q/A 검증
Q/A 쌍 생성

키워드 쿼리 생성

시퀀스 Q&A

RAG Q/A 검증

텍스트 요약
파라 요약
이메일 요약
대화 요약
파라 요약

이메일 요약
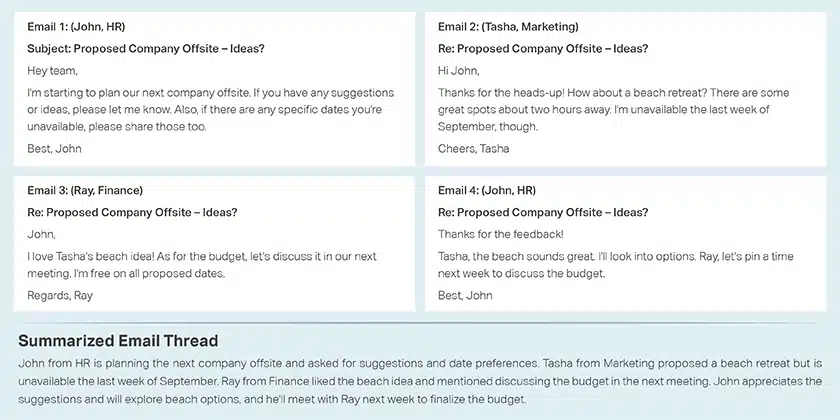
대화 요약
이미지 캡션

오디오 생성

LLM 데이터 평가

LLM 데이터 비교

합성 대화 생성
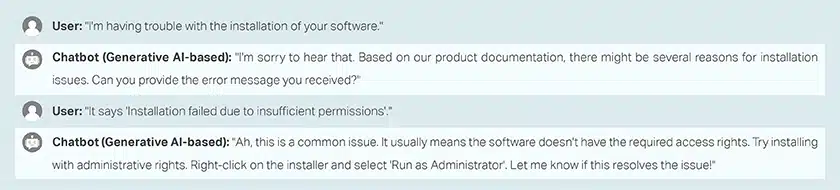
챗봇 교육 Q/A
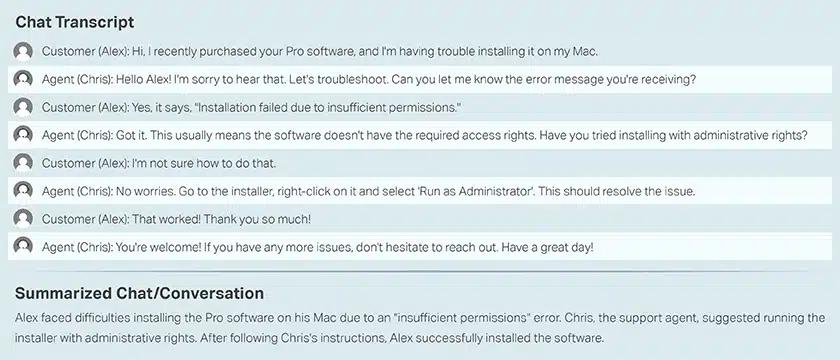
콜센터 대화 고객 및 상담원
챗봇 교육 Q/A
콜센터 대화 고객 및 상담원
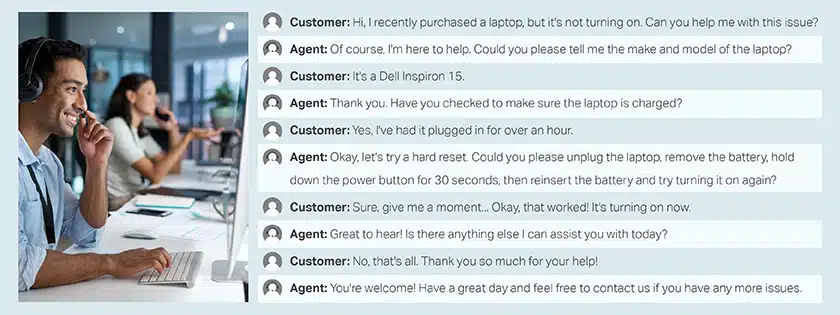
이미지 요약, 평가 및 검증
이미지 등급
이미지 검증
이미지 요약
이미지 등급
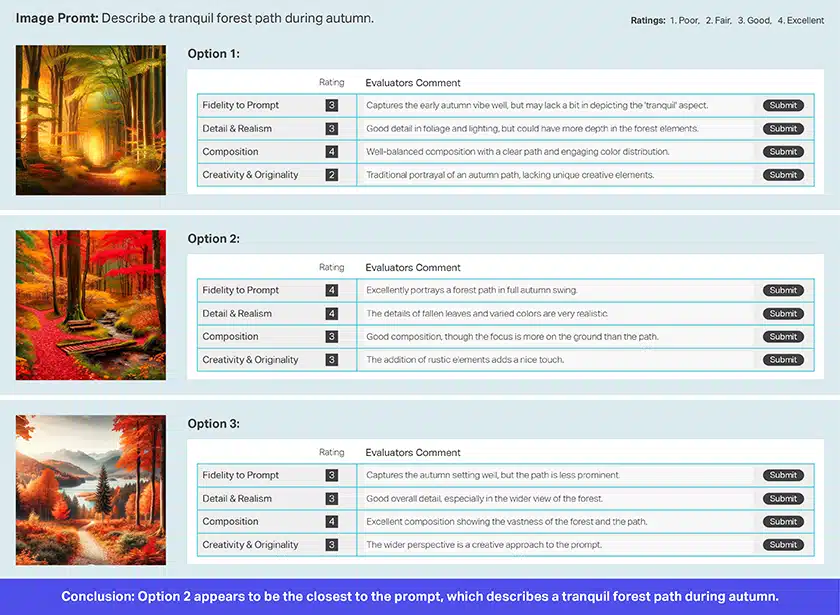
이미지 검증
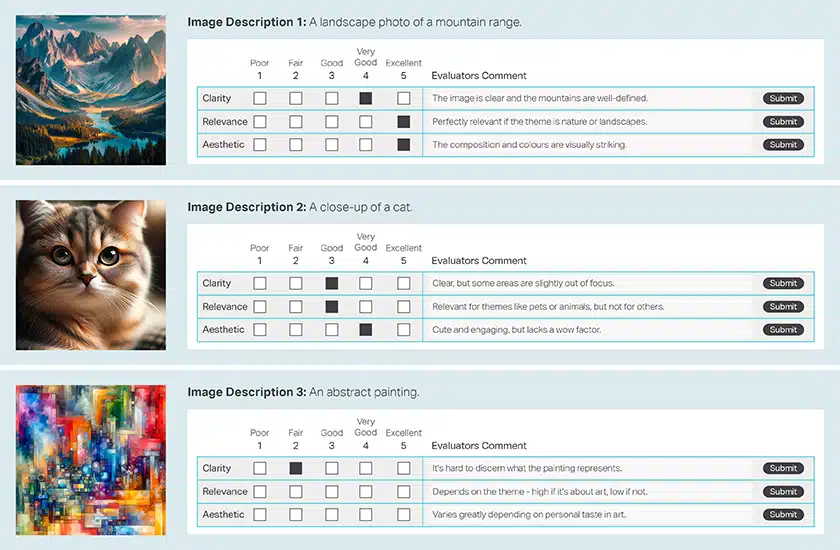
이미지 요약




임상 NLP를 만드는 것은 해결하기 위해 엄청난 도메인 전문 지식이 필요한 중요한 작업입니다. 이 분야에서 Google보다 몇 년 앞서 있다는 것을 분명히 알 수 있습니다. 나는 당신과 함께 일하고 당신을 확장하고 싶습니다.
구글, 주식 회사 책임자
내 엔지니어링 팀은 의료 음성 API를 개발하는 동안 Shaip의 팀과 2년 이상 협력했습니다. 우리는 의료 관련 NLP에서 수행한 작업과 복잡한 데이터 세트로 달성할 수 있는 것에 깊은 인상을 받았습니다.
구글, 주식 회사 엔지니어링 책임자