



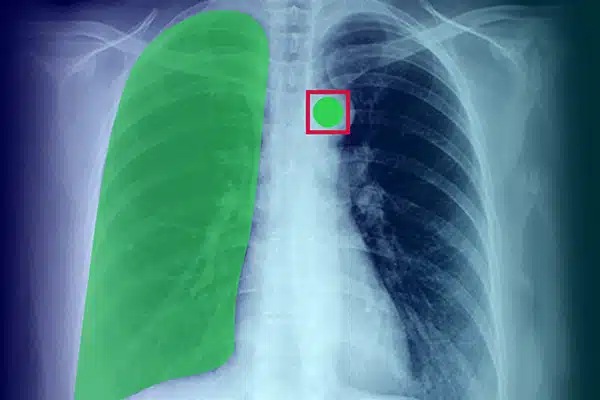
이미지 주석
X선, CT 스캔, MRI의 시각적 데이터에 주석을 추가하여 의료 AI를 강화합니다. 전문가 데이터 라벨링에 따라 AI 모델이 진단 및 치료에서 탁월한 성능을 발휘하도록 보장합니다. 우수한 영상 통찰력으로 더 나은 환자 결과를 얻으십시오.
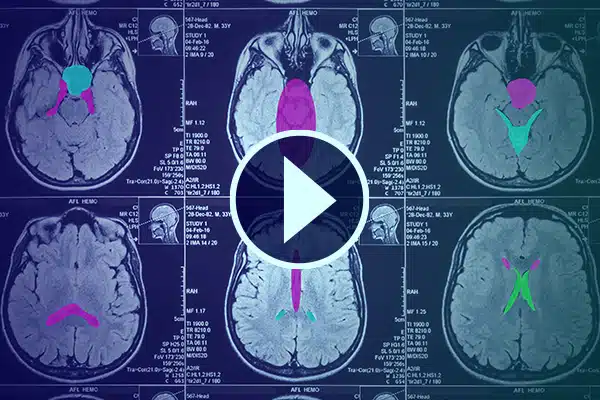
비디오 주석
상세한 비디오 주석을 통해 의료 분야의 AI를 발전시키세요. 의료 영상의 분류 및 세분화를 통해 AI 학습을 강화하세요. 의료 서비스 제공 및 진단 개선을 위해 수술 AI 및 환자 모니터링을 개선하세요.
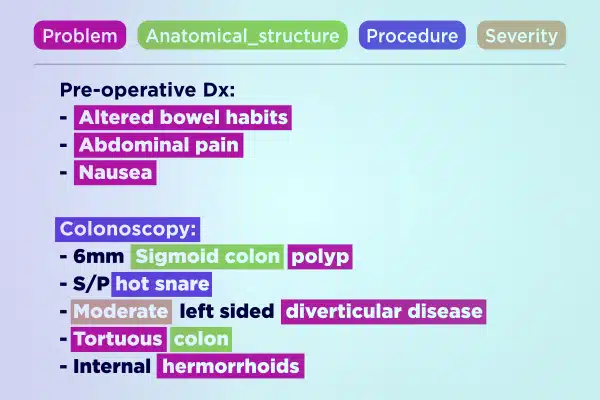
텍스트 주석
전문적으로 주석이 달린 텍스트 데이터로 의료 AI 개발을 간소화하세요. 손으로 쓴 메모부터 보험 보고서에 이르기까지 방대한 양의 텍스트를 신속하게 분석하고 강화합니다. 의료 발전을 위한 정확하고 실행 가능한 통찰력을 보장합니다.

오디오 주석
NLP 전문 지식을 활용하여 의료 오디오 데이터에 정확하게 주석을 달고 레이블을 지정합니다. 원활한 임상 운영을 위한 음성 지원 시스템을 제작하고 AI를 다양한 음성 활성화 의료 제품에 통합하세요. 전문적인 오디오 데이터 큐레이션을 통해 진단 정확도를 높입니다.

의료 코딩
AI 의료 코딩을 통해 의료 문서를 범용 코드로 변환하여 간소화합니다. 의료 기록 코딩 분야의 최첨단 AI 지원을 통해 정확성을 보장하고 청구 효율성을 높이며 원활한 의료 서비스 제공을 지원합니다.

위상 1 : 기술 도메인 전문 지식(범위 및 주석 지침 이해)

위상 2 : 프로젝트에 적합한 리소스 교육

위상 3 : 주석 문서의 피드백 주기 및 QA
방사선과
당사의 방사선 이미지 주석 서비스는 AI 진단을 강화하고 전문성을 강화합니다. 각 X-ray, MRI 및 CT 스캔에는 해당 분야 전문가가 꼼꼼하게 라벨을 지정하고 검토합니다. 훈련 및 검토의 이러한 추가 단계는 이상과 질병을 발견하는 AI의 능력을 향상시킵니다. 고객에게 배송되기 전에 정확성이 향상됩니다.

순환기내과
심장학에 초점을 맞춘 이미지 주석은 AI 진단을 향상시킵니다. 우리는 복잡한 심장 관련 이미지에 라벨을 붙이고 AI 모델을 훈련시키는 심장학 전문가를 초빙합니다. 고객에게 데이터를 보내기 전에 전문가들은 각 이미지를 검토하여 최고의 정확성을 보장합니다. 이 프로세스를 통해 AI는 심장 상태를 보다 정확하게 감지할 수 있습니다.
치과 의술
치과 분야의 이미지 주석 서비스는 AI 진단 도구를 향상시키기 위해 치과 이미지에 라벨을 붙입니다. 충치, 정렬 문제 및 기타 치아 상태를 정확하게 식별함으로써 SME는 AI가 환자 결과를 개선하고 치과의사가 정확한 치료 계획 및 조기 발견을 할 수 있도록 지원합니다.


















사람들
전담 및 훈련된 팀:
- 데이터 생성, 라벨링 및 QA를 위한 30,000명 이상의 공동 작업자
- 자격을 갖춘 프로젝트 관리 팀
- 경험이 풍부한 제품 개발 팀
- 인재 풀 소싱 및 온보딩 팀

방법
최고의 공정 효율성은 다음을 통해 보장됩니다.
- 강력한 6시그마 스테이지 게이트 프로세스
- 6시그마 블랙벨트로 구성된 전담 팀 – 핵심 프로세스 소유자 및 품질 준수
- 지속적인 개선 및 피드백 루프

플랫폼
특허 받은 플랫폼은 다음과 같은 이점을 제공합니다.
- 웹 기반 엔드 투 엔드 플랫폼
- 완벽한 품질
- 더 빠른 TAT
- 원활한 전달



