






텍스트 컬렉션

오디오/음성 컬렉션
텍스트 주석
오디오/음성 주석

텍스트 전사

오디오/음성 전사




대화형 AI / 챗봇 교육
디지털 비서 교육에는 다양한 지역, 언어, 방언, 설정 및 형식의 고품질 데이터가 많이 필요합니다. Shaip에서 우리는 필요한 지식, 도메인 전문 지식을 갖추고 있으며 클라이언트의 특정 요구 사항을 잘 알고 있는 Human-in-the-loop가 있는 AI 모델에 대한 교육 데이터를 제공합니다.
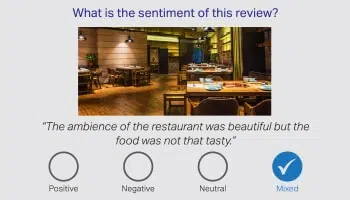
감정/의도
Analysis
단어만으로는 전체 이야기를 전달할 수 없으며 인간 언어의 모호성을 해석하는 책임은 인간 주석가에게 있습니다. 따라서 대화를 바탕으로 고객의 감성을 파악하는 것이 가장 중요합니다. 다양한 영역의 언어 전문가가 제품 리뷰, 금융 뉴스 및 소셜 미디어의 미묘한 차이를 해석할 수 있습니다.

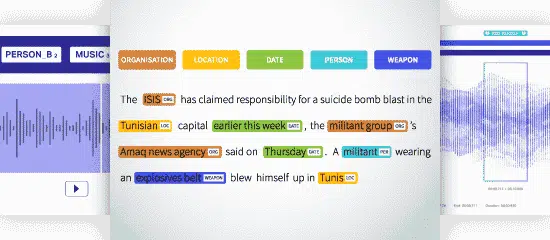
NER (Named Entity Recognition)
NER(Named Entity Recognition)은 텍스트 내의 명명된 엔터티를 미리 정의된 범주로 식별, 추출 및 분류합니다. 텍스트는 장소, 이름, 조직, 제품, 수량, 가치, 백분율 등으로 분류될 수 있습니다. NER를 사용하면 기사 등에서 언급된 조직과 같은 실제 질문을 해결할 수 있습니다.
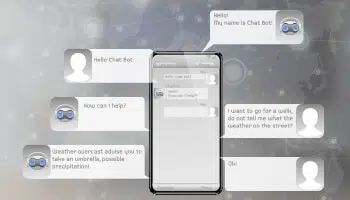
클라이언트 서비스 자동화
강력하고 잘 훈련된 가상 챗봇 또는 디지털 어시스턴트는 고객이 판매자와 통신하는 방식을 혁신하여 고객 경험을 크게 개선했습니다.

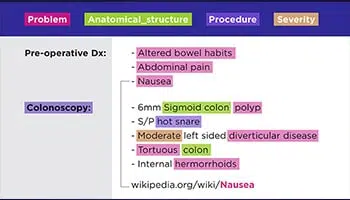
텍스트 전사
의사의 손으로 쓴 처방전부터 회의록에 이르기까지 당사 전문가는 보관 문서, 법적 계약서, 환자 건강 기록 등 모든 형태의 데이터를 디지털화할 수 있습니다.
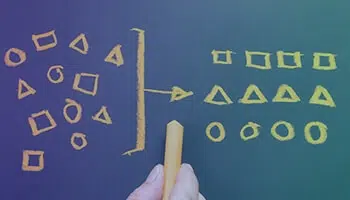
콘텐츠 분류
분류 또는 태깅이라고도 하는 분류는 관심 있는 기능에 따라 텍스트를 조직화된 그룹으로 분류하고 레이블을 지정하는 프로세스입니다.

주제 분석
주제 분석 또는 주제 라벨링은 고려 중인 반복되는 주제/주제를 식별하여 주어진 텍스트에서 의미를 식별하고 추출하는 것입니다.

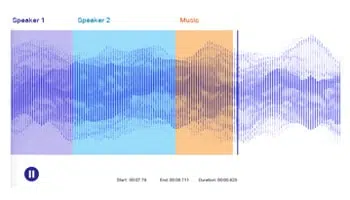
오디오 전사
연설/팟캐스트/세미나, 통화 대화를 텍스트로 변환합니다. 사람을 활용하여 오디오/음성 파일에 정확하게 주석을 달아 NLP 모델을 정확하게 훈련시킵니다.

오디오 분류
언어, 방언, 의미론, 어휘 등을 기반으로 음성/오디오를 분류하기 위해 소리 또는 발화를 분류합니다.

사람들
전담 및 훈련된 팀:
- 데이터 생성, 라벨링 및 QA를 위한 30,000명 이상의 공동 작업자
- 자격을 갖춘 프로젝트 관리 팀
- 경험이 풍부한 제품 개발 팀
- 인재 풀 소싱 및 온보딩 팀

방법
최고의 공정 효율성은 다음을 통해 보장됩니다.
- 강력한 6시그마 스테이지 게이트 프로세스
- 6시그마 블랙벨트로 구성된 전담 팀 – 핵심 프로세스 소유자 및 품질 준수
- 지속적인 개선 및 피드백 루프

플랫폼
특허 받은 플랫폼은 다음과 같은 이점을 제공합니다.
- 웹 기반 엔드 투 엔드 플랫폼
- 완벽한 품질
- 더 빠른 TAT
- 원활한 전달


