
인공 지능은 자동화된 구성, 마스터링 및 연주 도구를 제공하여 음악 산업에 혁명을 일으키고 있습니다. AI 알고리즘은 참신한 구성을 생성하고, 히트를 예측하고, 청취자 경험을 개인화하여 음악 제작, 배포 및 소비를 변화시킵니다. 이 신흥 기술은 흥미진진한 기회와 도전적인 윤리적 딜레마를 모두 제공합니다.
기계 학습(ML) 모델은 작곡가가 교향곡을 쓰기 위해 음표가 필요하듯이 효과적으로 작동하려면 교육 데이터가 필요합니다. 멜로디, 리듬, 감성이 얽히는 음악계에서 양질의 트레이닝 데이터의 중요성은 아무리 강조해도 지나치지 않습니다. 예측 분석, 장르 분류 또는 자동 변환을 위한 강력하고 정확한 음악 ML 모델 개발의 중추입니다.
ML 모델의 생명선인 데이터
기계 학습은 본질적으로 데이터 기반입니다. 이러한 계산 모델은 데이터에서 패턴을 학습하여 예측 또는 결정을 내릴 수 있도록 합니다. 음악 ML 모델의 경우 교육 데이터는 종종 디지털화된 음악 트랙, 가사, 메타데이터 또는 이러한 요소의 조합으로 제공됩니다. 이 데이터의 품질, 수량 및 다양성은 모델의 효율성에 상당한 영향을 미칩니다.

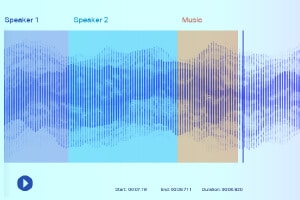
사운드 라벨링
사운드 레이블 지정을 사용하면 데이터 주석 작성자에게 녹음이 제공되며 필요한 모든 사운드를 분리하고 레이블을 지정해야 합니다. 예를 들어 특정 키워드나 특정 악기 소리가 될 수 있습니다.

음악 분류
데이터 주석자는 이러한 종류의 오디오 주석에서 장르나 악기를 표시할 수 있습니다. 음악 분류는 음악 라이브러리를 구성하고 사용자 추천을 개선하는 데 매우 유용합니다.

음성 수준 세분화
아카펠라를 노래하는 개인의 녹음 파형 및 스펙트로그램에서 음성 세그먼트의 레이블 및 분류.
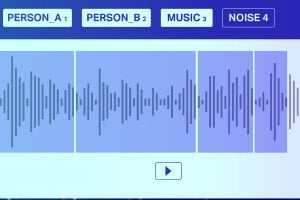
사운드 분류
무음/백색 소음을 제외하면 오디오 파일은 일반적으로 음성, 재잘거림, 음악 및 소음 사운드 유형으로 구성됩니다. 정확도를 높이기 위해 음표에 정확하게 주석을 답니다.
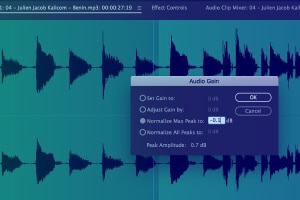
메타데이터 정보 캡처
시작 시간, 종료 시간, 세그먼트 ID, 음량 수준, 기본 사운드 유형, 언어 코드, 화자 ID 및 기타 표기 규칙 등과 같은 중요한 정보를 캡처합니다.


